예전부터 내가 제일 관심이 많았던 분야가 MSA, 대규모 트래픽 처리, 고가용성 아키텍처, 동시성 처리이다. 즉, 종합적으로 말하자면 "대규모 시스템 설계"에 대해서 많은 관심을 가지고 있었다. 하지만, 내가 여러개 프로젝트를 진행했음에도 불구하고 제일 많이 사용자를 유치한 것은 30여명의 사용자를 유치했던 "외국민" 프로젝트이다. 아마 프로젝트를 진행해본 사람들은 잘 알 것이다. 실사용자 100여명을 채우는 것은 굉장히 힘든 일이다. 즉, 내가 관심 있는 분야인 MSA, 대규모 트래픽 처리 등등은 경험하기 힘들고 오히려 MSA로 설계하면 오버엔지니어링인 경우가 많다.
그래서 솔직히 실제 우리 프로젝트에 적용하기에는 오버엔지니어링이고, 유지보수 시간과 비용이 너무 많이 들어서 개인적으로 대규모 시스템 설계에 대해서 공부해보고 구현해보고자 이 시리즈를 시작하게 되었다.
Monolithic Architecture와 Microservice Architecture (MSA)
일반적으로 많이들 프로젝트를 진행한다면 Monolithic Architecture로 진행하는 경우가 많다. 왜냐하면, MSA 아키텍처는 다루기 너무 힘들고 고려해야되는 부분이 너무나도 많기 때문이다. 실제로 옛날에는 대부분 Monolithic Architecture로 시스템을 설계하는 것이 흔했다.
Monolithic Architecture란, 소프트웨어의 모든 구성요소가 한 프로젝트에 통합되있는 것을 의미한다. 예시로, 내가 외국인 유학생 지원 서비스를 만든다고 해보자. 그럼 공지사항 기능, 채팅 기능, 로그인 기능, 학식 기능, 게시판 기능 등등이 한 프로젝트 안에 다 통합되있고, 하나의 서버로 운영되는 것이다. 소규모 프로젝트에서 굉장히 적합한 형태이며 간단하고, 고려해야될 포인트도 굉장히 적고, 유지보수도 훨씬 용이해집니다. 그런데 그만큼 한계도 있습니다.
- 서비스 규모가 커지면 커질수록, 어떤 영향을 주는지, 시스템 구조 파악 등이 매우 힘들어진다.
- 새로운 기능을 만들어서 배포를 하려고 해도, 빌드 시간이나 테스트 시간, 배포 시간이 기하급수적으로 늘어난다.
- 서비스를 부분적으로 scale-out하기 힘들다.
- 서비스의 한 지점에서 발생한 오류가 전체 서비스 장애로 이어지기도 한다.
이러한 단점이 있기 때문에 새롭게 대두되는 것이 바로 마이크로 서비스 아키텍처인 것이다! 간단하게 설명하자면 마이크로 서비스(MSA)란 위에 일체형 아키텍처의 기능들을 쪼개서 개발하는 것이라고 생각하면 된다. 예를 들어서, 위에 유학생 지원 서비스를 예시로 들면 채팅 서버, 로그인 서버, 학식 서버, 게시판 서버, 공지사항 서버 이렇게 나눈다.
마이크로서비스 아키텍처는 몇가지를 목표로 두고 일체형 아키텍처를 작은 컴포넌트로 나눈다.
- 빠르게 개발해 지속적으로 배포할 수 있어야 한다. 해당 서비스는 스스로 돌아 갈 수 있는 작은 서비스 형태가 되어야 한다.
- 수동 혹은 자동으로 쉽게 스케일링할 수 있어야한다.
MSA 말만들으면 굉장히 좋은 아키텍처처럼 보인다.
- 서비스 기능 별 개별적으로 배포가 가능하니, 배포를 하더라도 전체 서비스 중단이 없다.
- 쉽게 스케일링이 가능하다.
- 장애가 전체 서비스로 확장될 가능성이 낮다.
- 서비스 간 독립성으로 인해 확장성과 유연성이 높아진다.
- 개발을 할 때, 기능별로 팀을 나눠서 개발할 수 있어 협업이 용이해진다.
정말 이상적인 것 처럼 보인다. 그래서 대규모 시스템 설계에 대한 이해 없이 "와! 우리 프로젝트도 MSA를 도입해야겠구나!"라고 생각하고 도입하면 망한다. 왜냐하면 장점이 있으면 그만큼 큰 단점들도 있기 때문이다.
- 한 기능을 이루기 위해서 여러 서비스 간 통신이 필요한데, 이 때 연결 구축 과정이나 관리 복잡성이 매우 증가한다.
- 서비스 간의 통신 비용이나 Latency가 늘어난다.
- 서비스가 분리되어 있기 때문에 테스트와 트랜잭션 복잡도가 굉장히 늘어난다.
- 고려해야될 점이 굉장히 많기 때문에 초기 개발 및 통신 체계 구축에 굉장히 많은 시간이 소요된다.
- MSA를 고가용성으로 운영하기 위해서 여러가지 기술 스택을 도입해야되는데, 이에 대한 Learning Curve도 있고, 관리해야될 포인트도 늘어난다. 즉, 자칫하다가 유지보수가 오히려 어려워질 수 있다.
이래서 우리 서비스가 사용자 수도 별로 없는 서비스인데 MSA를 도입하는 것은 굉장히 안좋은 선택지고 오버엔지니어링이 된다.
MSA 설계시 고려해야될 포인트
MSA 설계시 고려해야될 포인트를 몇가지 소개해보겠다.
로드 밸런싱 (Load Balancing)

한 서버에 많은 사용자가 몰리면 그 서버는 과부하가 올 것이다. 그래서 트래픽을 고르게 분산하는 로드 밸런싱을 고려해야된다. Nginx로도 많이 하고, 클라우드 환경이면 ELB 같은 것도 많이 쓴다.
스케일 아웃 (Scale-out)
우리가 사용자가 1000여명 정도 모일 것으로 예상해서 서버를 마련해두고 로드 밸런싱을 적용했다. 그런데 생각보다 더 많은 사용자가 몰릴 것이다. 그러면 서버의 CPU나 RAM을 추가하는 등 자원을 늘리는 Scale-up을 수행할 수도 있지만, 대규모 시스템 설계에서는 오히려 서버 대수를 더 늘리는 Scale-out 확장법이 더 적절하다. 접속하는 사용자에 따라서 자동으로 Scale-out되는 Auto Scale Out도 고려할 수 있다.
서비스 검색 (Service Discovery)
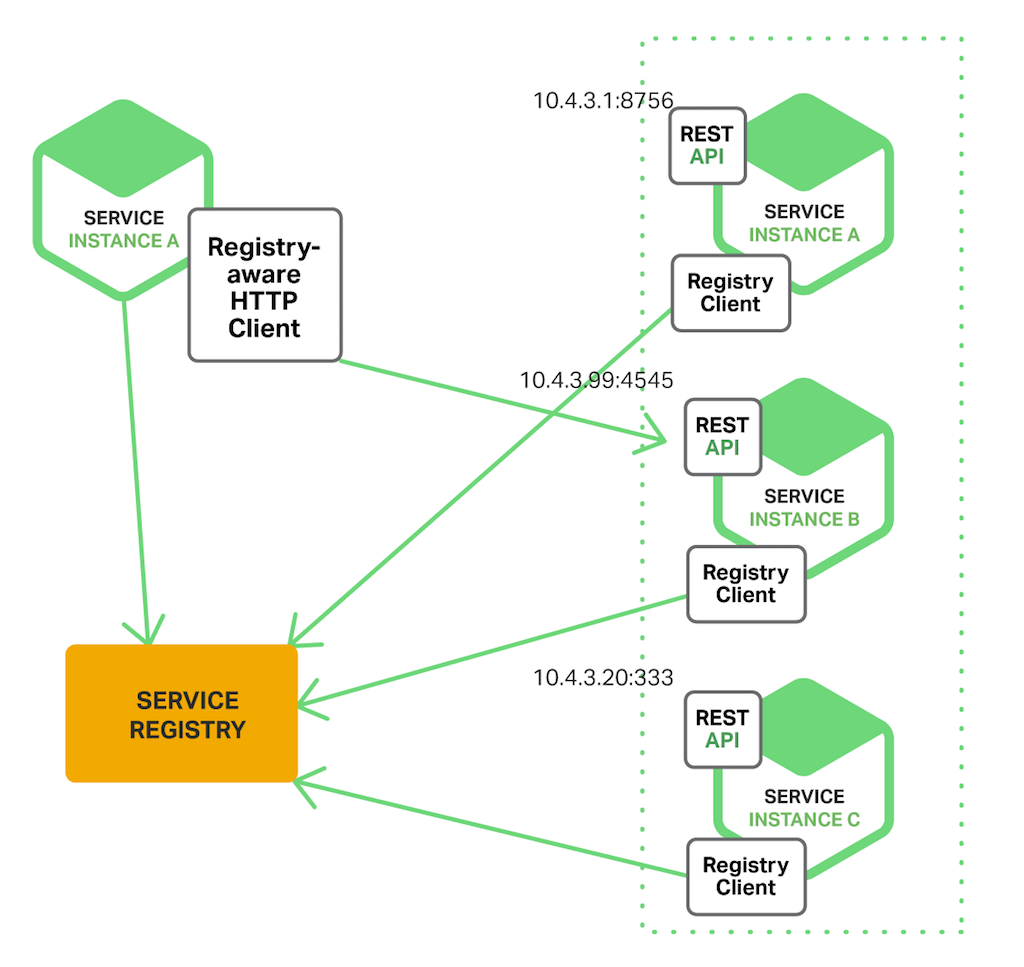
Scale-out한 인스턴스들은 시작하면서 동적 IP 주소를 할당받는다. 즉, IP 주소가 계속 바뀌니깐 HTTP 기반의 REST API를 호출하는 것이 어렵다. 그래서 현재 사용 가능한 마이크로서비스의 인스턴스를 추적하는 Service Discovery 컴포넌트가 필요한 것이다. 대표적으로 Spring Eureka같은 것이 있다.
에지 서버 (Edge Server)

마이크로서비스 환경에서 일부 마이크로 서비스만 외부로 노출 시키고, 나머진 외부에서 접근하지 못하도록 숨기는 것이 바람직하다. 또한, JWT 확인 같은 기능은 공통적으로 각각 서비스마다 필요한 기능이라 전부 구현하면 코드 중복이 많아진다. 따라서, 마이크로 서비스 젤 앞단에 이런 것들을 공통으로 처리하는 서버가 있으면 좋지 않겠는가? 그래서 필요한 것이 Edge Server이다. API Gateway의 일종이라고 생각하면 편하다. 대표적으로 Spring Cloud gateway가 있다.
처리율 제한 장치 (API Rate Limiter)
클라이언트가 보내는 트래픽의 처리율을 제한하기 위한 장치이다. 예시로 우리가 챗봇을 만들었는데 누가 악의적으로 우리 챗봇에 1초에 1000만번 요청을 보내면 우리 GPT 토큰이 모두 소모될 것이다. 이렇듯, 사용자가 특정시간동안 최대 얼마까지의 요청을 보낼 수 있도록 제안하는 장치가 바로 API Rate Limiter이다. 주로 Token Bucket Algorithm으로 많이 구현한다. Bucket4j 같은 라이브러리를 사용해서도 많이 구현한다.
리액티브 마이크로서비스 (Reactive MicroService)
일반적으로 SpringMVC로 개발하면 동기적 블로킹 I/O 모델로 통신이 진행된다. 운영체제를 배웠으면 알겠지만, 블로킹 I/O를 사용하면 사용자의 요청을 처리하는 동안, 그 스레드를 점유한다. 하지만, 동시에 굉장히 많은 유저가 몰린다면 가용 스레드가 부족해서 응답시간이 늦어지거나, 서버가 중단될 수 있다. 또한, 지연시간이 증가했는데 이 지연 시간 증가가 다른 클라이언트들에게도 전파될 수 있다. 따라서, 비동기 논블로킹 I/O를 사용해 개발하는 것이 Reactvie MicroService이다. 대표적으로 Spring Webflux같은 것들이 있다.
동시성 (Concurrency)
운영체제를 배웠다면 Race Condition이라는 말을 들어봤을 것이다. 변수 a = 0 값이 있는데, 갑자기 동시에 1만명의 대규모 사용자가 a값을 1씩 늘리는 행위를 한다고 해보자. 그러면 예상되는 값은 10000이지만, Race Condition이 발생해서 10000보다 못한 숫자 8200 정도로 나올 수 있다. 따라서, 이런 동시성 예방에 대한 생각을 해둬야한다. 일반적으로 DB Lock, DB Transaction 레벨 조정, 분산락 등의 방법을 이용하여 해결한다.
구성 중앙화 (Configuration centralization)
일반적으로 애플리케이션은 여러 환경 변수나 파일에 담긴 구성 정보와 함께 배포된다. 하지만, 마이크로서비스가 많아지면 많아질수록 이를 관리하기 너무 어려워진다. 따라서, 이런 구성 정보를 한곳에서 관리하도록 구성 중앙화를 하면 좋다. 대표적으로 Spring Cloud Config가 있다.
로깅 중앙화 (Logging centralization)

이것도 위랑 비슷한 맥락인데, 수많은 서비스들이 있다면 각각 로깅을 할텐데, 이러면 굉장히 관리가 어려워진다. 따라서, 로깅 분석을 중앙화하면 좋다. 대표적으로 Kafka + ELK Stack 두개를 합친 형태를 많이 사용한다.
분산 추적 (Distributed Tracing)
복잡한 분산 시스템에서 요청의 흐름을 추적하고 모니터링 할 필요가 있다. 예시로, 한 사용자가 어떤 기능을 작동시켰는데 문제가 발생했다. 그럼 이 장애를 해결하기 위해 문제를 일으킨 마이크로서비스를 찾고 근본적인 원인을 어떻게 밝힐 것인가? 아니면 특정 엔티티와 관련된 문제를 지원하고자 이와 관련된 모든 로그 메시지를 찾고 싶다고 해보자. 해당 주문 처리에 관여한 모든 서비스들의 로그 메시지를 찾으려면 어떻게 해야될까? 이래서 필요한 것이 분산추적이다. 대표적으로 Jaeger나 Zipkin등이 있다.
캐싱 (Caching)
캐싱은 서비스의 응답시간을 대폭 줄일 수 있는 아주 좋은 기술이다. 우리가 특정 사이트로부터 공지사항을 크롤링 해오고, 이를 목록으로 보여주는 기능을 구상했다고 해보자. 그리고 이 공지사항은 24시간에 한번만 크롤링을 해와 자주 바뀌지 않는 정보라고 가정해보자. 그런데 자주 바뀌지도 않는데 매번 RDB에서 정보를 읽어오면 어떨까? 가뜩이나 리스트 형태여서 많은 정보를 읽어와야하는데, 자주 바뀌지도 않는데도 매요청마다 읽어오면 매우 비효율적이고 성능에 치명적일 것이다. 따라서, 자주 바뀌지 않는 정보는 메모리에 캐싱을 해두면 빠르게 사용자의 요청에 응답할 수 있게 된다.
이에 대해서는 다른 내용이 이미 있다. 참고하길 바란다.
[대규모 시스템 설계] 캐시 설계 전략
캐싱 설계 전략 왜 필요한가?캐싱은 서비스의 응답시간을 대폭 줄일 수 있는 아주 좋은 기술이다. 우리가 특정 사이트로부터 공지사항을 크롤링 해오고, 이를 목록으로 보여주는 기능을 구상했
mclub4.tistory.com
대표적으로 Redis나 Memcached를 이용하여 많이 한다.
서비스간 통신
마이크로서비스에서 서비스간 통신을 하는 경우가 굉장히 많다. 하지만, 우리가 이 모든 통신을 REST로 한다면 어떨까?
REST는 HTTP/1.1 프로토콜을 사용하기 때문에, 단일 request에 대해서 단일 response만 제공해준다. 즉, 여러번의 request를 보내서 서버에 처리를 요청해야 된다. 그러면, 불필요한 네트워크 비용이 발생하며, 성능도 저하가 된다. 요즘같이 MSA가 업계 표준이 되가는 상황에서, 서비스간 통신이 진행될 일이 굉장히 많을텐데, 이 점은 굉장히 치명적일 것이다.
그래서 해결하기 위해 등장한 기술이 Socket, RPC와 같은 기술이다. 여기서, 구글이 기존의 RPC 성능을 높여 만든 프레임워크가 바로 GRPC이다.
이에 대한 내용은 아래를 참고 바란다.
[대규모 시스템 설계] GRPC를 통한 서비스간 통신
서비스간 통신 어떻게 진행할까?일반적으로 우리가 MSA 구조에서, 서비스와 서비스간 통신한다라고 한다면 직관적으로 떠오르는 것은 Endpoint를 생성해서 REST를 이용해서 통신하는 것이다. 하지
mclub4.tistory.com
Messsage Broker
MSA에서 우리가 여러 서비스마다 서버를 나누어 실행한다. 하지만 서비마다 작업해야되는 내용들을 동기적으로 통신하면 리소스를 많이 잡아머는다. 자 예시로 임시저장 기능을 들어보자. 우리가 임시저장을 했고, 서버에서는 처음에는 원본 데이터만 저장하고, 이후에는 바뀐 부분만 저장하는 식으로 구성된다 해보자. 그러면 이 바뀐 부분을 계산하는 서버가 필요한데, 데이터 크기가 커지면 조금 오래걸리는 작업일 수 있다. 만약 이를 동기적으로 통신한다면 지연시간이 굉장히 커지고 장애 전파가 일어날 가능성이 크다. 따라서, 그냥 "너 시간 날때 작업해"라고 Message Queue에 던져두고 비동기적으로 작업하게 두는 것이 바로 Message Queue이다.
이를 도입하면 서버간 Coupling이 줄어들고, 확장성을 높일 수 있다. 대표적으로 Kafka나 RabbitMQ 등이 있다.

그런데 여기서 또 고려해야될 점이 있다. 만약에 우리가 주문 기능을 구현하다고 해보자. 그럼 주문이 발생하면 사용한 캐시, 포인트 등 금액을 차감하고, 상품을 지급하며 주문 완료로 바꾸는 DB 트랜잭션이 발생할 것이다. 그리고 그 이후 Message Broker에 주문 완료 메시지를 publish 하는 것이 일반적이다. 하지만... 트랜잭션이야 뭐 atomic을 보장하므로 상관없지만, Message Broker와 DB는 다른 것이다. 따라서, 주문이 완료되더라도 Message Broker에 publish가 실패할 수 있고, DB 주문 완료 처리를 롤백하는 것이 매우 어려워진다.
그래서 나온 패턴이 위 그림에서 보이는 Transactional outbox 패턴이다. Transactional outbox 패턴은 그냥 간단히 얘기하자면 트랜잭션에서 Message Broker에 publish하는 과정까지 포함시키는 패턴이라 생각하면 된다. Outbox라는 것이 "보낸 편지함"이라는 의미를 가지는데, Outbox table이라는 메시지를 보낸 편지함 테이블을 만들고, Message Relay가 이 테이블로부터 순서대로 읽어서 이벤트를 발행해주는 형태인 것이다. 주로 이런 Message Relay 구현을 위해 Debezium 같은 도구를 활용하기도 한다. 배달의 민족 테크 유튜브에 이에 대한 내용을 소개하는 것도 있으니 보면 좋을 것 같다.
뿐만 아니라, Message Broker를 설계할 때는 순서보장, 고가용성적인 부분도 고려해야된다. 일단 순서보장 같은 경우는 일반적으로 이를 위해 Kafka를 많이 사용한다. 그 다음 이제 고가용성적인 부분인데, 이게 참 어렵다. 고가용성 보장을 위해 최소 3대의 Kafka 서버를 준비해야되고, 그 내부에서도 토픽에서 파티션에 대해서 Replica도 생각해줘야된다. 아직 이부분은 공부가 부족한 관계로... 추후 글을 작성하면서 더 자세히 써보겠다.
DB 다중화 및 분산

대규모 시스템 설계에서 일반적으로 Master-Slave 패턴을 이용하여 저장을 많이 한다. 그런데, 우리가 서비스를 운영하면 데이터베이스를 삽입하는 연산보다 읽기 연산 비중이 훨씬 높다. 따라서, 이 읽기 DB를 다중화하고 분산할 필요가 있다.
또한, 서비스 규모가 점점 커져 데이터가 많아지면 데이터 베이스에 대한 부하도 굉장히 많이 증가한다. 이것도 역시 앞서 설명한 Scale-up과 out으로 해결할 수 있다. scale-up은 DB 성능을 높이는 방법이다. 하지만, SPOF (Single Point Of Failure)가 발생할 가능성이 굉장히 높아서 조심해야된다. 그래서 많이들 하는 방법이 Scale-out 방식의 "데이터베이스 샤딩"이다. user DB가 있다면 DB를 4개 구축하고 user_id % 4 값에 따라 어느 DB에 저장할지 결정하는 방식이다.
그런데 이 샤딩을 할 때도 고려할 점이 굉장히 많다. 대표적인 것이 유명인사 문제이다. 예를 들어 뉴진스가 1번 DB에 들어가있다면 너무 유명인사여서 이쪽에 너무 몰려 과부하가 오는 것이다. 또다른 문제로는 데이터 조인이 어려워진다는 것이다. 추가로 더 샤딩을 해야될 경우 데이터베이스를 추가해야될 수도 있다. 하지만 이러면 기존에 우리가 구축한 샤딩이 깨져버린다. 그래서 이게 깨지지 않도록 안정 해시 기법을 이용해서 설계해야 된다.
유일 ID 생성
우리가 분산 DB를 구축 했고, User DB를 분산했다고 해보자. 그럼 User ID는 PK이며 유일해야될 것이다. 하지만, 우리가 DB를 분산했기 때문에 이를 하기가 쉽지 않다. 그래서 유일성이 보장되는 ID를 만들기 위해 설계할 필요가 있다. 대표적으로 UUID, 티켓 서버, 트위터 스노플레이크 접근법 등이 있다.
DB 분산 트랜잭션 관리
MSA 환경에서는 우리가 각각 마이크로서비스마다 DB를 구축하는 것이 일반적이다. 그런데 여러개 서비스가 긴밀하게 협력하여 하나의 일을 수행하는 것이 마이크로서비스인데, 만약에 A -> B ->C 기능 순서대로 시행되야 하는데, A,B 는 정상적으로 됐는데 C에서 실패한다면 어떻게 해야될까? 당연히 A, B를 롤백해야된다. 이에 관한 것이 바로 분산 트랜잭션 관리이다. 대표적인 기법으로는 Two-Phase Commit (2PC), Choreography based SAGA pattern, Orchestration based SAGA pattern 등이 있다.
Key-Value 저장소 설계
앞서 우리가 DB 분산 설계한 것처럼, Redis 같은 Key-Value 저장소도 분산 설계할 수도 있다. 하지만, 이 키는 유일해야되는데 분산 환경에서 각각 개별적으로 Key를 생성하면 충돌날 가능성이 매우 크다. 그래서 나온 것이 분산 키-값 설계인 CAP 정리이다.
서킷 브레이커 패턴
동기 방식으로 상호 통신하는 마이크로서비스 시스템 환경은 연쇄 장애가 발생할 여지가 있다. 하나의 마이크로서비스가 응답하지 않는다면, 이 마이크로서비스의 클라이언트 또한 요청에 응답하지 않는다. 이 문제는 시스템 환경 전체에 재귀적으로 전파돼 중요한 부분까지 중단시켜버릴 수 있다. 따라서, 대상 서비스에 문제가 있다는 것을 감지해 새 요청을 보내지 않도록 회로를 차단하는 느낌의 서킷 브레이커 패턴이 필요하다. 대표적으로 Resilience4j가 있다.
모니터링 및 경고 중앙화
갑자기 어떤 서비스의 CPU가 치솟고, 메모리가 초과되고, 응답시간이 지나치게 높고 이러면 해결하기가 꽤 어렵다. 따라서, 마이크로서비스 인스턴스가 사용하는 하드웨어 자원 사용량에 대한 메트릭을 수집하는 것이 있으면 좋다. 대표적으로 Prometeus + Grafana 나 Datadog 등이 있다.
온프라미스 환경 vs 클라우드 환경
자체적으로 시스템을 구축해서 스스로 돌릴 온프라미스를 택할지, 아니면 AWS, Azure, GCP, NCP 등의 클라우드 플랫폼을 이용할지 고민해야된다. 클라우드 환경에서도 어떤 것을 쓸지 많이 고민할 수 있다. 예를 들어 EC2 같은 것을 쓸수도 있고, ECS같은 컨테이너 배포 형태도 쓸 수 있다. 또한, Serverless 형태의 Lambda를 쓸 수도 있는 것이다.
컨테이너화
컨테이너화는 애플리케이션을 독립적인 컨테이너로 패키징하여 일관된 환경에서 실행될 수 있도록 하는 기술이다. 이를 통해 마이크로서비스의 배포, 확장 및 관리를 용이하게 할 수 있다. 예를 들어서, 우리가 개발을 python 3.1, 라이브러리 pandas의 버전은 1.1로 개발했다고 해보자. 그리고 이를 실제 배포 환경에 옮기면, 아마 환경이 달라서 충돌이나서 작동하지 않을 가능성이 높다. 따라서, 일관된 실행 환경 구축을 위해 컨테이너화를 하는 것이다. 대표적으로 Docker가 있다.
또한, 이렇게 만들어진 Image를 저장할 Registry도 필요하다. 대표적으로 Dockerhub, ECR, Harbor 등이 있다.
컨테이너 오케스트레이션
마이크로서비스 아키텍처에서 컨테이너 오케스트레이션은 수많은 컨테이너를 효율적으로 관리하고 운영하는 데 필수적인 역할을 한다. 오케스트레이션 도구는 컨테이너의 배포, 확장, 모니터링 및 관리를 자동화하여 복잡한 시스템 환경에서도 안정적이고 효율적인 운영을 가능하게 한다. 예를 들어, 우리가 MSA를 개발하고 띄워져있는 컨테이너만 20여개가 된다고 해보자. 우리가 이걸 다 하나하나 관리할 자신이 있는가? 없다. 그래서 필요한 것이 컨테이너 오케스트레이션이다. 제어루프 패턴이라고도 볼 수 있다. 대표적으로 Kubernetus, EKS, Docker Swarm 등이 있다.
서비스 메쉬
서비스 메쉬는 마이크로서비스 같은 서비스 간의 통신을 제어하고 관찰하는 인프라 계층이다. 서비스 메시는 마이크로서비스 사이의 전체 내부 통신을 제어하고 모니터링해 관찰 가능성, 보안, 정책 시행, 탄력성, 트래픽 관리 등의 기능을 구현한다. 이를 통해 개발자들은 애플리케이션 로직에 집중할 수 있고, 통신 관련 기능을 서비스 메쉬가 처리하도록 할 수 있다. 즉, MSA 환경에서 서비스 간 통신을 효과적으로 관리하고 최적화 함으로써 애플리케이션의 안정성과 보안 및 운영 효율성을 높이는 것이다. 대표적으로 Istio가 있다.
CI/CD
우리가 매번 새로운 버전이 올라올 때 마다 클라우드에 접속해 배포하는 것은 매우 어렵다. 그래서 나온 것이 이를 자동화하는 파이프라인을 구축하자는 것이다. CI/CD 파이프라인을 구축하면 자동으로 테스트를 돌리고, 이를 실제 환경에 배포를 진행한다. 대표적으로 Github Actions, Jenkins, ArgoCD 등이 있다.
무중단 배포
우리가 시스템 새로운 버전이 나와서 배포를 진행한다고 해보자. 그러면 기존 서비스를 내리고 다시 올릴 것이다. 그러면 그 사이에 짧은 시간 동안 서비스가 중단되는 사태가 발생한다. 따라서, 필요한 것이 무중단 배포 개념이다. 대표적으로 블루-그린 배포, 카나리 배포 방식 등이 있다.
이렇듯, 대규모 시스템 설계를 위해서는 고려할 점이 너무너무너무 많고 알아야 될 것도 너무 많다. 그래서 소규모 프로젝트에는 적합하지 않다는 것이다.
앞으로 위에서 설명한 MSA에서 고려해야될 점에 대해서 각각 자세히 다뤄볼 예정이다. 순서는 위에서 무작위로 작성할 예정이다.
'BackEnd > 대규모 시스템 설계' 카테고리의 다른 글
| [대규모 시스템 설계] Kafka의 기초 (1) | 2024.11.15 |
|---|---|
| [대규모 시스템 설계] 동시성 처리 (0) | 2024.07.04 |
| [대규모 시스템 설계] GRPC를 통한 서비스간 통신 (2) | 2024.05.22 |
| [대규모 시스템 설계] 캐시 설계 전략 (0) | 2024.05.20 |


