해당 글에서는 내가 백엔드 개발을 하면서 고려했던 것과 아쉬웠던 점을 다루고자 한다. 해당 내용은 우리 프로젝트 소개 페이지에도 서술되어있다.
💾 Backend 기술 문서
외국인 유학생을 위한 앱서비스
kookmin-sw.github.io
일단 내가 담당한 기능들에 대해 소개해보고자 한다.
- 공지사항 크롤링 및 커서 기반 페이지네이션 기능
- 로그인/회원가입 기능
- JWT 토큰 발급 기능
- 채팅 기능
- 발음평가 관련된 치명적인 오류 수정
- 전반적인 시스템 아키텍처 설계
- API Gateway 구축 (JWT Token 확인 및 API Rate Limiter 구축)
- Https 적용
- Docker Container화
- Git Actions을 이용한 CI/CD 적용
- Test Container를 활용한 테스트 환경 구축
- 캐싱을 통한 응답시간 향상
- 전반적인 인프라 및 배포에 관련된 내용 진행
- Apache Jmeter를 통한 부하 테스트
- Swagger를 통한 API 문서화 도입
나는 전반적인 배포 및 시스템 개발을 담당했다.
기능적 고려 사항
채팅 구현
채팅 서버는 크게 Polling, Long Polling, Steaming, Websocket 방식으로 구현할 수 있다. 앞선 3가지 방법은 일반적인 RESTFUL API를 이용한 구현 방법이다. 그래서 비교적 구현이 쉽다. 하지만, 이들의 특성상 클라이언트 → 서버로 데이터 전송이 가능하지만, 서버 → 클라이언트로 전송은 불가능하다. 또한, 100% 실시간성을 보장하지 않는다. 이를 극복하기 위해서 나온 방법이 바로 4번 WebSocket 방식이다. 그런데 채팅을 websocket으로 구현하면, 굉장히 리소스를 많이 잡아먹고 구현이 까다롭다.
그래서 우리 서비스는 Long Polling을 이용하여 채팅을 개발하기로 결정했다. 우리 서비스의 채팅은 100% 실시간성을 보장할 필요 없을 뿐더러, 채팅이 메인 비즈니스 기능이 아니고, 프로젝트 마감기한이 임박하여 빠르게 개발해야되기 때문에 Long Polling을 이용하여 채팅을 개발하기로 결정했다.
채팅 시스템 설계 및 시나리오에 관한 더 자세한 내용은 채팅 구현에 대한 고찰 필자의 블로그에 서술해놓았다.
크롤링
현재 크롤링은 학식과 공지사항 분야에서 실시되고 있다. 크롤링 할 때도 몇가지 고려할 사항이 존재한다.
첫번째, 정적 크롤링과 동적 크롤링 어떤 것이 필요한가 고려해봐야 한다. 공지사항과 학식은 굳이 로그인을 하지 않아도 누구나 접근할 수 있기 때문에 굳이 동적 크롤링이 필요하지 않았다. 또한, 동적 크롤링은 Selenium 라이브러리를 이용하고, Chrome Driver를 설치하는 등 추가적인 설정이 매우 복잡하다. 따라서, 사용이 간단한 Jsoup을 이용해서 정적 크롤링을 진행하기로 결정했다.
두번째, 크롤링은 외부 네트워크와 통신하여 이루어진다. 그래서 네트워크 I/O 병목지점을 어떻게 해결할것이고 이 때 자원을 최대한 아낄 수 있는지 고려해봐야 한다. 따라서, 크롤링은 Async를 이용하여 비동기적으로 처리되도록 하여 병목 현상을 줄이도록 하였다.
세번째, 공격적인 크롤러는 상대 서버에게 무리를 줄 수 있다. 따라서, 크롤링을 진행할 때 상대 서버에 부담을 줄일 수 있도록 고려해야한다. 그래서, 학식같은 경우는 국민대 학식 API가 존재하여 이를 이용하여 정보를 가져왔다. 하지만, 공지사항은 이런 API가 없기 때문에 다른 방법을 고려해야된다. 따라서 크롤링 횟수를 하루에 2번으로 줄였고, 되도록 사람이 적게 몰리는 새벽 또는 식사 시간대에 크롤링을 진행하도록 구성했다. 또한, 웹사이트의 robots.txt을 준수하여 크롤링이 허용되지 않은 영역은 진행하지 않았다.
네번째, Jsoup를 이용하여 크롤링을 진행하였는데, Jsoup은 정적 메소드만 제공해서 테스트가 어렵다는 점을 고려해야 한다. 그래서 이를 해결하기 위해 단위테스트시 Mockito같은 라이브러리를 이용하여 테스트를 진행하면 된다. 하지만, 이 부분은 시간이 부족하여 고려만하고 진행하지 못하였다. 추후, 다른 프로젝트를 진행할 때는 이 점을 고려하여 테스트를 진행할 예정이다.
발음 연습
발음 연습 구현을 위해서 Azure에서 제공하는 Speech Service를 사용하였다.
그런데, 발음 연습이 분명히 Local에서는 잘됐음에도 불구하고, Docker로 Container한 후, 클라우드 서버에 올리니
Could not initialize class com.microsoft.cognitiveservices.speech.SpeechConfig
위와 같은 오류가 발생하였다.
이유는 Spring Docker를 위해, JDK 경량화 이미지인 alpine을 사용했는데, SDK 설치 설명서를 확인해보면 Debian 또는 Ubuntu 환경에서만 작동한다고 명시되어 있다. 그래서 alpine이 아닌 ubuntu 기반의 JDK Image를 사용해서 Build를 하였다.
하지만, 또다른 오류가 발생하였다. 모든 점수가 0점이 나오는 오류였다. 이유는 역시 설명서에 명시되어 있었다.

설명서를 잘 보면, Ubuntu 22.04는 기본값이 OpenSSL 3.0인데, 이는 지원하지 않는다고 한다. 그리고, Docker Build를 위해 사용한 eclipse-temurin:17-jdk는 Ubuntu 22.04이다. 따라서 기존 3.0버전의 Open SSL을 지우고, 1.1 버전을 설치하는 과정이 필요했다. 그래서 Speech SDK Github Issue에 올라와있는 OpenSSL 다운그레이드 하는 방법을 참고하여 새로 Dockerfile을 작성하여 고쳤다.
자세한 Dockerfile은 필자 블로그의 Azure 발음평가 해결과정 포스팅을 참고해주면 감사하겠다.
API Gateway
JWT 확인 로직과 API Rate Limiter는 채팅서버, 챗봇서버, 메인 서버 모두 필요한 로직이다. 하지만, 이를 각각 서버마다 구현하는 것은 매우 비효율적이고 코드 중복이 많아진다. 따라서, API Gateway를 구축하여 모든 요청이 이를 통과하도록 구성하면 매우 효율적이다.
하지만, API Gateway를 SpringMVC로 구현하는 것은 매우 비효율적이다. SpringMVC의 WAS는 Tomcat인데, Tomcat은 요청이 들어오면 ThreadPool에서 Thread를 하나 배정해준다. 또한, 각 요청을 동기적으로 처리하고, 동기적으로 처리하는 동안 해당 스레드는 블로킹 된다. (비동기 처리가 불가능한 것은 아님. 하지만 비동기 처리를 하더라도 어찌됐던 간에 ThreadPool을 소모하니깐, ThreadPool 고갈 문제는 여전) 그래서 동시에 많은 요청이 들어올 경우 스레드풀이 고갈되어, 성능이 저하될 수 있다. 따라서, API Gateway로 적합하지 않다. 그래서 택한 것이 Spring Cloud Gateway이다.
Spring Cloud Gateway는 Netty 기반이다. Netty는 논블로킹 비동기 Event-driven 구조이다. 그래서 빠르게 대규모 트래픽을 처리해줘야하는 API Gateway 구조에서 Netty가 적합하다. 이를 통해 적은 양의 스레드와 최소한의 자원으로 효율적으로 요청을 처리할 수 있었다.
다만, Spring Cloud Gateway말고도, AWS에서 제공하는 API Gateway를 이용하는 방법도 있을 것으로 보인다. (하지만, 이는 코드 레벨 관리가 아니라 인프라 레벨에서의 관리라서 살짝 차이가 있음)
로깅
로깅은 우선 할 수 있는 만큼 최대한 많이, 그 다음에 필요 없는 로그는 지우거나 레벨을 낮추는 식으로 운영하는게 좋다. 그래서, 로깅은 두가지 부분에서 처리를 하였다.
첫번째, API Gateway단에서 모든 Request를 Logging한다. 이곳에서 요청한 url, method, request body, Authorization Header를 Logging 하였다. 이로써, 한 곳에서 공통적으로 Logging을 처리할 수 있게 되었다.
두번째, Spring에서 AOP를 이용하여 메서드별 실행 시간 기록을 진행하였다.

위와 같이 Spring 서버에서 구성을 하여, 메서드별 실행 시간을 쉽게 측정할 수 있다.
API 응답 및 문서
Response로 받는 Json 형식이 정해져있지 않다면, 프론트 개발자들은 매번 API 문서를 참고하여 매번 그에 맞춰 수정해야될 것이다. 따라서, 프론트엔드에서 모듈화하여 유연하게 Response를 받을 수 있게 하기 위해 API 공통 응답을 설계했다. 공통 API 응답 설계는 카카오의 API 공통응답 기술문서를 참고하였다.

성공했을 때는 위와 같이 성공 여부를 알려주는 success, 그에 대한 message, 그리고 응답에 대한 결과값인 response로 구성된다. response안에 이제 프론트 측에서 원하는 결과가 담겨있다.

실패했을 때는 success가 false, 실패에 대한 message, 그리고 오류 코드를 알려주는 code로 구성된다. 해당 오류 코드는 서버 측에서 Enum으로 정의되어 있으며, 테스트를 용이하게 위해서 만들었다.

API 문서는 Swagger를 사용하였다. 소프트웨어공학에서 Agile Process에 대해서 과도한 문서화를 하지 말라고 언급하였다. 특히, API 문서화 같은 경우는 계속해서 응답 형식이나 파라미터 등이 변할 수 있는데, 매번 API 문서를 최신화 하는 것도 어렵고, 서버와 문서가 서로 안맞는 정합성 문제가 발생할 수도 있다. 그러면, 오히려 문서를 유지보수하거나 오류를 해결하는데 Cost와 Time을 증가시킨다.
따라서, Swagger를 이용하여 API가 변경되더라도 자동으로 API 문서를 최신화 해도록 구성하였다. 이로써, API 문서를 유지 보수하는데 시간을 크게 줄일 수 있었다. 또한, Swagger를 통해 API 문서에서 바로 테스트를 진행해볼 수도 있어서 협업의 능률을 향상시켰다.
배포
AWS EC2 인스턴스에 배포한다던지, 컴퓨터와 노트북을 번갈아가며 개발하다던지, 이러면 각각 개발 환경이 틀려 매번 설정을 해주어야 한다. 하지만 Docker가 있다면? 귀찮게 그럴 필요 없이 쉽게 배포를 진행할 수 있다. 따라서, 실행하는 OS 환경에 상관없이, 언제나 같은 환경에서 결과를 낼 수 있도록 Docker Container화를 진행했다. Ruby On Rails나 AI서버의 Docker Container화는 다른 것과 별반 다를게 없는데, Spring Container화를 좀 특이하게 진행하였다. 일반적인 Docker 배포 방식으로 Spring 서버를 배포한다면, jar 파일이 무거워질수록 docker image를 만드는 과정이 비효율적으로 된다. 그런데, Docker의 장점이 레이어마다 캐쉬를 사용하고, 이를 통해 빠르게 이미지를 만들 수 있다는 것이다. 하지만, 해당 방식으로 진행하면 소스 코드를 한줄만 바꿔도 캐쉬가 깨지기 때문에 다시 연산을 해야되서, Docker를 사용하는 장점이 없어진다. 왜냐하면, Spring의 모든 애플리케이션 코드와 라이브러리가 Single layer에 배치되기 때문이다. 결국 컨테이너 환경에서의 시작 시간에도 영향을 미친다.
그래서 Multistage Build와 Jar 파일의 특성 두가지를 고려해서 Dockerfile을 작성했다. 우선, 일반적인 방식으로 Docker Image를 생성시, 우리는 jar 파일만 필요한데 쓸데없는 소스 코드까지 다 포함하게 되어서 용량이 지나치게 커지고, 업로드하는데도 오래 걸리게 된다. 따라서, MultiStage Build를 이용하여 Build할 때만 필수적인 코드로 jar 파일을 생성하고, 최종 Docker image에는 이것들이 포함되지 않도록 설정했다.

또한, Spring 공식 Docs를 들어가보면 Spring의 Jar 파일은 위 사진과 같이 4가지 Layer로 나뉜다고 한다. 해당 문서에서, application layer가 가장 자주 바뀌고, 그다음은 snatphot, 그다음은 spring-boot-loader, dependencies 순으로 자주 바뀌지 않는다고 한다. 즉, Dependencies가 가장 바뀌지 않는다는 것이다. 그러면 Dockerfile을 작성할 때, Docker File은 제일 자주 바뀌지 않는 것부터 차례로 작성해주는 것이 좋기 때문에 이것의 역순으로 Docker File을 작성하였다.
CI/CD로 대표적인 것은 Jenkins와 Git Actions가 있는데, 우리는 Git Actions을 택했다. 그 이유는 Github에서 관리하는 것이다 보니깐, 코드 저장소랑 바로바로 연결이 되고, PR을 생성하게 되면 GitHub Actions를 통해 해당 코드 변경 부분에 문제가 없는지 각종 검사를 진행할 수도 있기 때문이다.

위와 같은 플로우로 Github에서 자동으로 서버들이 배포될 수 있도록 Git Actions 설정을 해놨다.
setup-env에서 git actions secret으로부터 받은 .env를 생성한다. 그리고 이걸 우리 ec2에 scp 프로토콜을 이용해서 전송한다. 또한, 실질적인 서버 배포를 담당한 docker-compose.yml도 scp 프로토콜을 통해서 전송한다.
그 다음, 우리의 spring, ruby, spring gateway, nginx 등을 docker image로 build한다. 그런데 여기서 문제가 있다. Git Actions는 매번 새로운 RunTime 환경에서 실행되기 때문에, docker의 이점인 docker cache를 적용하지 못한다. 그래서 Build 할 때 굉장히 시간이 오래걸린다. 따라서, cache를 적용하기 위해서 docker에서 공식적으로 제공해주는 docker buildX를 이용했다. BuildX를 사용하면, Git Actions 내부적인 Cache 저장소를 활용하여 Docker Cache를 저장할 수 있다. 실제로, BuildX를 적용하기 전에는 Spring Container 빌드 시간이 13 ~ 15분 정도 걸렸다. 하지만, 캐시를 적용한 이후로는 위 사진에서 보이는 것 처럼 5분으로 Build 시간이 10분 가까이 줄어들었다.
마지막으로, 우리 ec2에 ssh로 접속해서 이미지를 내려받고 docker-compose를 실행하여 배포를 완료하도록 구성했다.
성능적 고려 사항
캐싱
유저들이 자주 접근하는 데이터는 캐싱하는 것이 좋다. 예를 들어서, 공지사항 목록이나 Q&A 목록인 경우, 자주 바뀌지도 않을텐데 유저들이 해당 게시판에 접속할 때마다 매번 RDB에서 목록을 읽어오는 것은 비효율적이다. 따라서, Redis같은 곳에 캐싱해두고, 똑같은 요청이 들어오면 빠르게 Redis에서 뽑아가도록 구성했다. 캐싱 전략은 다음과 같다.
캐싱 전략은 Look Aside와 Write Around 전략의 조합을 택하였다. Read 전략은 Look Aside 전략을 활용했다. 우선적으로 Redis에서 읽어오고, cache miss가 발생했을 때만, RDS에서 읽어오고 다시 redis에 저장하는 방식이다. Write 전략은 Write Around 전략을 활용했다. 데이터를 쓸 때, Redis에 저장하지 않고, 반드시 RDB에 저장하고 기존 캐시는 무효화하는 전략이다.
실제 캐싱을 적용하기 전과 후의 시간을 측정해보았다.
캐싱 전에는 메서드를 실행하는데 414ms가 걸렸다.

하지만 캐싱 후에는 12ms로 단축되었다. 실행시간이 1/40 단축된 것이다.

그런데 캐싱된 데이터를 받으면, class 정보에 대한 field가 json에 추가되는 현상이 있어서 추가 보류를 하였다.
또한, 이미지를 받아오는 S3도 캐싱을 무조건 해야한다. 그렇지 않으면 S3 비용이 굉장히 많아질 것이고 응답시간이 길어진다. 그래서 AWS CloudFront를 S3 앞단에 두어 캐싱될 수 있도록 구성했다.
비동기 처리
모든 요청을 동기적으로 처리하는 것은 매우 비효율적이다. 특히, 이미지를 업로드하거나, 번역 API 같은 다른 API에 요청을 보내거나, 크롤링 등은 매우 오래걸리는 작업이다. 이 모든 작업을 동기적으로 처리하면, 성능에 매우 치명적일 것이다. 그래서, 해당 기능들을 사용하는 경우에는 Async를 통한 비동기 처리를 실시하였다.
이 비동기처리를 위해서 Spring에서 ThreadExecutor를 이용한다. 그런데, 기본 Async Executor Simple Async Task Executor인데, 이는 비동기 작업마다 새로운 스레드를 생성한다. 이로 인해 리소스 낭비, 성능 저하, 스케일링 문제 등이 발생할 수 있다. 왜냐하면 Thread Pool 방식 Executor가 아니라서 스레드 재사용을 하지 않기 때문이다. 그래서 실행시간이 짧은 많은 양의 Task를 처리할 때 불리하다. 리소스 측면에서는 각 비동기 작업마다 새로운 스레드를 생성하므로, 동시에 많은 비동기 작업이 요청되면 매번 많은 스레드가 생성된다. 따라서 CPU와 메모리 리소스의 사용량이 과도하게 증가하는 문제가 발생할 수 있다. 성능 저하 면에서는 스레드를 생성하고 소멸시키는 데는 많은 시간과 리소스가 소요된다. 각 작업마다 스레드를 생성하면 이런 오버헤드가 계속 발생하게 되고, 전체적인 시스템 성능에 영향을 끼칠 수 있다. 또한, SimpleAsyncTaskExecutor는 스레드 수에 대한 제한이 없다. 따라서 동시에 많은 요청이 들어올 경우 스레드 수가 무한정으로 제어할 수 없는 수준으로 증가할 수 있으며, 이는 곧 OutOfMemoryError 등의 문제를 일으킬 수 있다.

그래서, 위 사진과 같이 Async의 Executor를 ThreadPool방식의 Executor로 설정했다. 이는, 사용할 스레드 풀에 속한 기본 스레드 수인 corepoolsize, corepoolsize가 가득 찬 상태에서 더이상 추가 처리가 불가능 할때, 대기하는 장소 크기인 queuecapacity, 스레드 풀이 확장될 수 있는 스레드의 상한선, 즉 스레드 수의 상한선인 maxpoolsize를 조정하여 ThreadPool방식의 Async Executor를 구성했다.
Race Condition 해결
프로젝트에서 답변의 추천기능을 구현하면서 추천 / 추천 해제 기능을 만들었다. 문제가 있다면 추천수, 조회수와 같은 기능은 하나의 필드에 대해 수많은 트랜젝션 요청이 오가는 기능이기 때문에 이경우 자원에 접근하는 것에 대한 Race Condition, 동시성 문제가 발생하게 된다. 이러한 경우를 해결하기 위해서 Redis를 사용하였다. Redis는 싱글 스레드로 자원에 대한 Race Condition 문제를 해결할 수 있기 때문이다. 이 문제를 해결하기 위해 Cache Write 전략중에서 Write Back 전략을 응용하였다. Redis에 요청을 보낼 countTemplate를 선언하고 이를 통해서 Redis에 객체와 답변의 추천수를 저장하고 일정시간마다 이렇게 Cache에 저장된 내용을 DB에 반영시키도록 하였다. 이렇게 Redis에 저장된 변경 사항은 30초 간격으로 DB에 반영되는 방식으로 구현하였다.
하지만, Redis를 이용하더라도 결국에는 Redis에서 값을 읽고 비교하고 쓰는 이 일련의 행위는 Spring 코드에서 Lock이 걸리지 않고 실행되기 때문에 Atomic하게 실행되지 않는다. 그래서 이 문제를 해결하기 위해 Redis Lock을 걸어주어 Atomic하게 실행되도록 보장하였다. 물론, 우리는 Redis Lock을 이용하였지만, 이외에도 Redis Transaction 이용, Redis 내부에서 Lua Script를 이용하여 Atomic하게 실행, DB Lock, DB의 Isolation Level 조정 등의 방법이 있을 것이다.
현재 방법도 동시성 문제를 해결하는 방법이지만 내가 추천한 답변의 추천수가 즉시 반영되어 보여지지는 않는다. 이는 데이터를 읽어올때는 캐시에서 찾는 방식이 아니기 때문이다. 추후에는 캐시에서 값을 찾도록 구현할 필요가 있다.
추가적으로, 운영체제 과목에서 캡스톤 인터뷰 과제 문서에 Race Condition 예방에 관련된 문서를 하나 만들었었다. 혹시라도 동시성 처리에 관심이 있다면 해당 문서에 2번을 참조해주길 바란다.
N+1 문제
여러 참조관계를 가진 테이블이 존재하고 비즈니스 로직에서 이들을 Join하여 호출하는 상황이 많이 있었으며 이때 N+1문제가 발생하였다. 이를 해결하기 위해 Fetch Join을 사용하거나 Projection 주입을 사용하는 경우의 Inner Join과 같이 여러 경우의 N+1의 해결 방법을 모색하여 적용하였다. 이로 인해 서버 비즈니스 로직의 성능향상이 이루어질 수 있었다. 이 과정에서 여러 시행 착오가 있었다. 기존의 방식은 Projection을 사용하여 DTO를 바탕으로 JPA 검색을 사용하는 방식이었는데 이 경우 Fetch Join이나 EntityGraph로는 해결이 불가능하다. @Projection을 사용한 해결 방안도 있으나 좀 더 고민해본 결과 Join의 목적에서 N+1문제를 야기할 필드값이 큰 문제가 없어 InnerJoin으로도 충분히 해결되는 범주였다는 것을 깨달았다.
또한, batch size를 조절해서 N+1 문제를 해결할 수도 있다. 하지만, 우리는 현재 서비스 초기라서 batch size로 영향이 갈 만큼의 데이터가 존재하지 않기 때문에 이 점은 보류하였다.
안정성 고려 사항
사용자 트래픽 제한
A라는 사람이 악의적으로 우리 AI 모델에게 1분에 100만번의 요청을 보낼 수 있다. 그러면 우리 AI Token은 모두 사라진다. B라는 사람은 Spring 비즈니스 서버에 1초에 1000만번 요청을 날린다. 그러면, 역시 서버가 터질 것이다. 따라서, 서버와 클라이언트 사이에서 미들웨어 역할을 하여 분당 API 사용량을 제한할 필요가 있다. 그래서 API Rate Limiter를 적용했다.

사용자가 최대 가질 수 있는 Token Bucket Capacity가 정해져 있다. 그리고 계속, 지속적으로 일정시간마다 Token이 리필이 된다. 이 Token 리필은 Bucket Size가 꽉찼을때는 되지 않는다. 그리고, 사용자가 API 요청을 보낼 때 마다 Bucket에서 Token을 꺼내간다. 만약, 꺼낼 Token이 없다면, Status 429를 보내준다. (Too Many Requests) 이외에도 누출 버킷 알고리즘, 고정 윈도 카운터 알고리즘, 이동 윈도 로깅 알고리즘, 이동 윈도 카운터 알고리즘 등이 존재한다. 하지만, 일반적으로 Token Bucket Algorithm을 많이 쓰기 때문에 이를 사용했다.

Redis는 인메모리 DB이기 때문에 매우 빨라서 적합하다. 또한, Redis의 또 다른 특징은 싱글 스레드에서 실행될 수 있다는 것이다. 그래서, 다중 사용자의 요청에도 일관되게 처리할 수 있다. 이를 이용하여 초당 사용자가 6~7번의 요청까지만 보내고, 아닐경우 429 Error를 보내도록 설정해서 트래픽 제한을 걸었다.

실제로 위에 사진처럼 Apache Jmeter로 시뮬레이션을 돌려보면, 429 Error를 반환하는 것을 볼 수 있다.
사용자 업로드 파일 용량 제한
외국민 서비스에는 발음평가와 게시판에서 이미지를 업로드 하는 기능이 존재한다. 이 상황에서, Client는 Server에 파일을 업로드 할텐데, 만약에 너무 크기가 큰 파일을 보낸다면 서버에 큰 부담을 줄 것이다. 그래서, Nginx를 이용하여 제일 최전방에서 빠르게 용량이 너무 큰 파일은 올리지 못하도록 차단하였다.
보안적 고려 사항
사용자 비밀번호 암호화
사용자의 비밀번호를 그대로 DB에 보관하는 것은 잘못된 일이다. 비밀번호를 암호화하지 않고 저장하면, DB가 해킹당했을 경우 큰 피해가 발생한다. 실제로, 비밀번호 암호화는 젤 기초적인 작업임에도 불구하고 하지않아 개인정보유출에서 큰 피해를 본 기업들이 많이 있다.
그래서, “외국민” 서비스는 Firebase를 이용하여 사용자의 ID와 비밀번호를 관리한다. Firebase는 비밀번호를 암호화해서 안전하게 잘 보관해주기 때문이다.
JWT를 통한 Authentication
Token은 서버가 각각의 클라이언트가 누구인지 구별할 수 있도록 사용자의 유니크한 정보를 담은 암호화된 데이터이다. 우리 서비스의 여러 기능들은 인증된 사용자만 접근 할 수 있도록 하는 것이 정상일 것이다. 따라서, 로그인시 Main Business Server에서 Access 및 Refresh Token을 발급해주고, 매 요청마다 Header로 AccessToken을 보내야 한다. 그러면 API Gateway서버에서 해당 토큰을 확인해보고, Invalid한 JWT Token일 경우 403 에러를 보내준다. 정상적인 Token일 경우, 해당 서버로 라우팅을 해주어 요청을 처리하도록 구성했다.
Token 탈취 상황 예방
JWT토큰은 탈취의 위험성이 있다. JWT기반 인증 방식에서는 세션과 다르게 Stateless하다는 특징이 있기 때문에, Token이 탈취당해도 우리 서버가 그걸 알아차리고 해당 Token을 중지시킬 수 있는 방법은 존재하지 않는다. 따라서, accessToken은 유효기간이 짧은 단위의 토큰으로 구성해야 한다. 주로 15분 정도로 구성하는 경우가 많다. 하지만, 이렇게 짧은 시간으로 설정한다면, 사용자는 계속해서 재로그인을 해야된다는 번거로움이 있다. 그래서 등장한 것이 Refresh Token이다.
Refresh Token은 AccessToken과 다르게 매우 긴 유효기간을 가지고 있다. Access Token과 Refresh Token을 사용할 때, 플로우는 아래와 같이 흘러간다.
- 클라이언트가 회원가입 혹은 로그인에 성공하면 서버는 응답값으로 Access Token과 Refresh Token을 함께 제공한다.
- 클라이언트는 API를 호출할 때 Access Token 담아 보내고, 서버에서 Access Token을 통해 유저를 인증한다.
- 만약 Access Token의 유효 기간이 만료되었다면, 클라이언트는 Refresh Token을 서버에 전달하여 새로운 Access Token을 발급받는다.
즉, Access Token과 Refresh Token으로 나누고, Access Token을 통해 통신함으로써, 악의적 이용자에 의해 Access Token이 탈취당하더라도 유효기간이 짧기에 크게 부담이 되지 않고, 주 통신은 Access Token으로 이루어지기 때문에 Refresh Token이 탈취당할 가능성을 크게 줄일 수 있다.
그런데 RefreshToken도 탈취당하면 어떻게하지?라는 생각이 들 수 있다. 그래서 많이 쓰는 방법이 Refresh Token Rotation(RTR) 방법이다.

Refresh Token Ratation(RTR)이란 Access Token이 만료되고 Refresh Token으로 새로운 Access Token을 받아올 때, 새로운 Refresh Token도 받아오도록 하는 방법이다. 즉. Refresh Token이 사용될 때마다 새로운 Access Token과 Refresh Token을 발급하여 이전에 발급된 Token들은 사용이 불가능하도록 한다.
AccessToken Ban
만약에 사용자가 로그아웃을 했다고 해보자. AccessToken의 기간이 만약에 30분인데, 5분만에 로그아웃을 했는데도, 그 Token가지고 요청을 보낼 수도 있다. 따라서, 로그아웃을 할 경우, Redis에 해당 AccessToken을 Ban을 해두어서 요청을 보내지 못하도록 설정했다.
HMAC
우리 서비스의 대부분에 AccessToken을 요구하더라도, 로그인 및 회원가입 같은 경우는 Token이 없는 상황에서 발생하는 요청이다. 하지만, 누군가 우리 Endpoint를 알아내고, Flutter 앱이 아닌 다른 곳에서 요청을 보낸다면 이는 비정상적인 요청일 것이다.

따라서, 회원가입 및 로그인 시에는 HMAC을 포함하여 요청을 보내도록 구성했다. 우리 Flutter 앱과 서버 모두 공통된 Secret를 가지고 있으며, 이 Secret을 가지고 우리 Request의 HMAC을 같이 보내도록 구성했다. 그러면, 우리 앱에서 보내지 않은 요청들은 모두 막을 수 있을 것이다.
환경변수 적용
JWT Secret, HMAC Secret, API Key 등등을 우리 Code에 Hard Coding해서는 절대 안된다. 따라서, env 파일로 환경변수를 분리하여 노출되지 않도록 설정했다.
테스트 고려 사항
Test Container를 이용한 가상 테스트 환경 구축
또한, 우리가 실제 서비스하는 RDS를 가지고 테스트를 진행한다면, 매우 위험할 것이다. 하지만, 통합 테스트 진행을 위해서 분명히 DB에 데이터를 저장하고 테스트 해봐야되는 순간이 존재한다. 따라서, 우리 서비스는 Test Container를 이용하여 MySQL, Redis 테스트 컨테이너를 만든 뒤, 독립된 환경에서 안전하게 테스트를 진행하도록 하였다.
Apache Jmeter를 이용한 부하 테스트
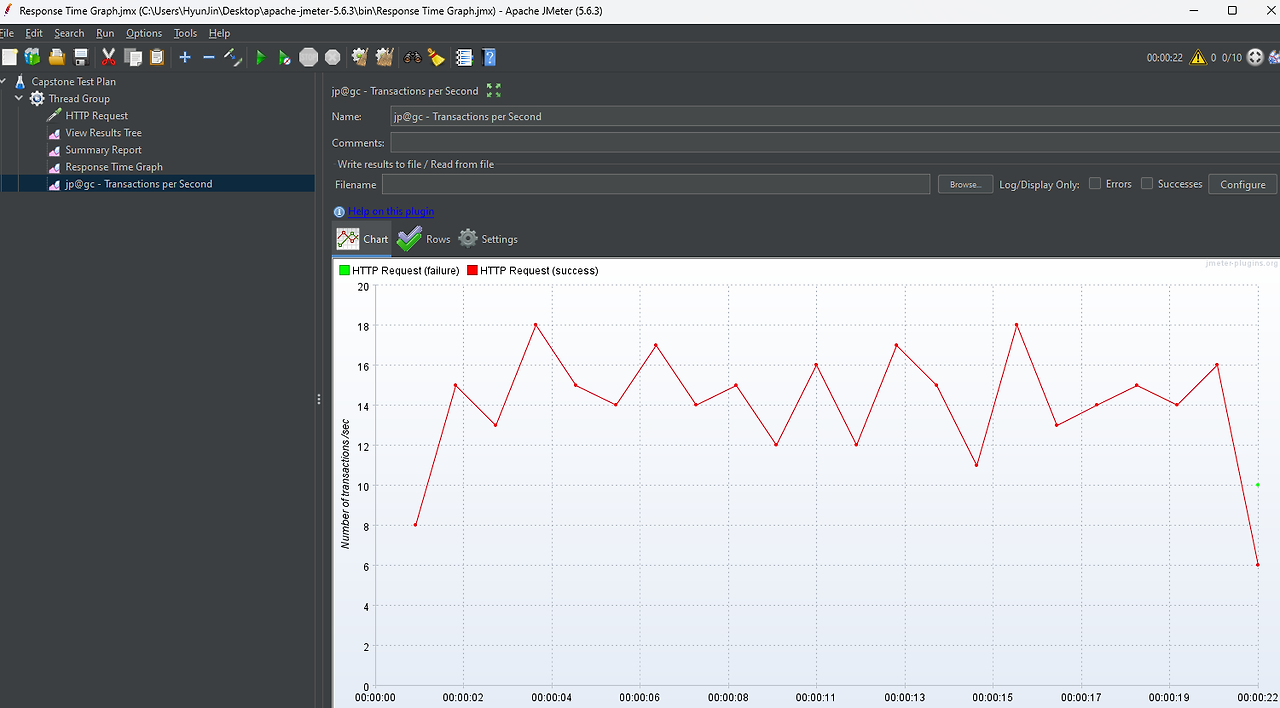
프로젝트에서 동시성 문제 테스트와 같이 대규모 부하 테스트를 위해서 사용하게 되었다. 이를 이용하여, 쉽게 대규모 트래픽을 생성하여 요청을 보내볼 수 있으며, 외부 플러그인을 이용하여 쉽게 TPS를 측정할 수도 있었다.
실제로 공지사항 리스트를 받아오는 API에 대하여 RPS를 측정해보니 2000 RPS 정도까지는 무리 없이 잘 처리한다. 이 이상으로는 부하 테스트를 진행해보지 않았지만, 더 가능할 것으로 보인다.
아키텍처 설계

기존 아키텍처는 위와 같이 구성했다. 하지만, 위의 아키텍처는 여러가지 문제점이 있었다. 우선, 우리 메인 Spring 비즈니스 서버는 다른거 처리하기도 바쁘다. 게다가, 채팅을 Long Polling으로 개발하였는데, 여러 사용자가 동시 다발적으로 요청을 보낸다? 그럼 메인 비즈니스 서버의 성능을 매우 떨어질 것이며, 응답시간은 길어질 것이다. 결국 Software Quality가 떨어질 것이다. 따라서 채팅 서버를 분리할 필요가 있다.
뿐만 아니라, api 요청을 보낼때 https가 아닌 http로 보내기 때문에 데이터의 Integrity를 보장할 수 없다. 그래서 요청을 https로 암호화해서 보낼 필요가 있다.
마지막으로, 챗봇, 메인 비즈니스 서버, 채팅 서버 모두 JWT Token을 확인하는 과정이 필요하다. 하지만, 위와 같이 디자인하면, 각각 서버에서 JWT Token을 확인하는 로직을 짜야되므로 비효율적이다. 또한, API 사용량 제한을 걸기 위해서 각각 API Rate Limiter를 구현해야한다. 따라서, API Gateway를 구축해 이를 처리하는 것이 좋다.

그래서 위와 같은 아키텍처로 변경했다.
우리 외국민 서비스 배포에 대한 과정은 아래 시리즈를 참고해주길 바란다.
[배포] "외국민" 서비스 배포 과정 - (1)
기존 서비스 아키텍처기존 아키텍처는 위와 같이 구성했다. 하지만, 위의 아키텍처는 여러가지 문제점이 있었다. 우선, 우리 메인 Spring 비즈니스 서버는 다른거 처리하기도 바쁘다. 게다가, 저
mclub4.tistory.com
현실적 제한 및 개선 필요 사항
검색 기능 개선
현재 게시물 및 공지사항 검색은 제목으로만 검색된다. 하지만, 이보다 제목 + 내용으로 검색이 가능한 것이 더 좋을 것이다. 이를 위해서 SQL Like 연산자로 내용까지 검색이 가능하긴 하나, Like 연산자는 선형 연산자이기 때문에 성능에 매우 치명적이다. 따라서, ElasticSearch를 이용해서 빠르게 검색하는 것이 더 좋을 것이다. ElasticSearch는 분산 검색 및 분석 엔진으로, 대규모 데이터에서 빠른 전체 텍스트 검색을 지원한다. 추후, ElasticSearch를 통해 우리 RDB에 저장된 글들을 역색인하여 거의 실시간에 가깝게 검색하도록 개선할 것이다.
테스트 진행 강화
현재 시간 부족으로 테스트 코드는 일부 시나리오에 대해서만 통합 테스트가 진행되고 있다. 하지만, 통합 테스트 뿐만 아니라 각각 Domain에 대하여 단위 테스트가 진행될 필요성이 있다. 따라서, 더욱 이상적인 CI/CD 파이프라인이 진행되기 위해서 테스트 코드를 강화할 필요가 있다.

또한, 현재는 우리 테스트 코드의 Code Coverage를 시각적으로 측정할 수 있는 방법이 없다. 그래서, 우리가 미쳐 생각하지 못한 시나리오나 Domain에 대하여 누락될 가능성도 있다. 그래서 추후 위 사진과 같이 Jacoco같은 라이브러리를 이용하여 우리 테스트 코드의 Code Coverage를 측정하고, html로 리포트를 생성하여 팀원들이 쉽게 볼 수 있도록 추출할 것이다.
인스턴스 성능의 한계

현재 우리서버는 Free Tier를 사용하여 견딜 수 있는 트래픽의 한계가 있는 상황이다. 이를 해결하기 위해서 수직적 확장 또는 수평적 확장을 고려할 수 있다. 현재 Free Tier 성능이 아닌 더 좋은 EC2 인스턴스를 사용하거나, 여러개의 EC2를 만들어 Load Balancing을 적용하여 Scale Out적인 확장을 할 수도 있다. 하지만, 현재는 비용적인 문제로 불가능한 상황이다.
무중단 배포
현재 우리 서비스는 Git Actions를 이용한 CI/CD를 적용하고 있다. 하지만, 현재 방식은 새 버전으로 서버가 배포될 때 반드시 1~2분정도 서버가 중단될 수 밖에 없다. 이는, 실제 서비스할 때 매우 치명적이다. 따라서, 무중단 배포가 반드시 필요하다.

무중단 배포 방식으로는 Rolling, Canary, Blue-Green 배포 방식 등 여러가지 방법이 있지만, 만약 우리가 무중단 배포를 구축한다면 Blue-Green 배포 방식을 적용할 것이다. Blue-Green이란 두 개의 동일한 환경인 “블루”와 “그린”을 사용하여 새로운 버전의 소프트웨어를 배포하고 롤백하는 방식이다. 블루 그린 배포 방식은 가장 많이 쓰이는 무중단 배포 방식이며, 카나리에 비해서 구현도 간단하고, Rolling 방식보다 훨씬 안정적이다. 따라서, 추후 Blue-Green 무중단 배포 환경을 구축할 계획이다.
로드 밸런싱
서버를 단일로 구성하면, 많은 트래픽이 몰렸을 때 감당하기 힘들 것이다. 따라서, 서버를 여러개 만들고, Load Balacning하는게 좋은 선택지일 것이다. 하지만, 로드 밸런싱을 하기엔 비용적인 문제 때문에 환경 구축이 어렵다. 왜냐하면, 여러개의 EC2를 띄워야되기 때문이다. 그래서, 어쩔 수 없이 단일 서버로 운영하게 되었지만, 추후 사용자가 늘어나면 로드 밸런싱을 적용할 계획이다.
모니터링 및 로깅 강화

우리 서비스의 전반적인 로깅을 하는 것도 중요하다. 현재 로깅은 Nginx 단에서 파일 저장으로 한번, API Gateway단에서 요청 url, body, Authorization으로 한번, 각 MSA 서버 단에서 한번 이루어진다. 하지만, 애플리케이션 단에서의 로그는 파일로 저장하고 있지 않아 우리가 직접 컨테이너에 접근해서 하나하나 찾아봐야한다. 또한, MSA 구조다 보니깐, 각각 컨테이너에 직접 접근해서 봐야한다는 문제점이 있다. 하지만, 이런식으로 진행하면 애플리케이션 로그를 검색하고 파악하는데 시간을 더 써서 서비스에 매우 치명적이다. 따라서, Kafka + ELK Stack을 통하여 비동기적으로 로그 데이터를 ELK Stack으로 전송하고, 이를 분석한 후, 대시보드 형태의 시각적인 데이터로 바꿔주는 시스템이 구축되어야 할 것이다.

또한, 서비스를 운영할 때 모니터링 및 성능 관리는 매우 중요하다. 우리가 24시간 365일 컴퓨터 앞에 상주하여 서버 모니터링을 할 수 없기 때문이다. 따라서, Prometheus + Grafana나 Datadog 등을 이용하여 우리 서비스를 모니터링 하는 환경은 필수적이다. 이런 환경을 구축해두면 서버의 CPU나 메모리 사용량이 급증 했을 때, 우리 팀 Slack으로 결과를 전송하고 대시보드로 현황을 쉽게 현황을 파악할 수 있을 것이다.
컨테이너 오케스트라제이션

현재 우리 서비스는 MSA 구조에 가까운 형태여서 수많은 Container들이 돌아가고 있다. 돌아가는 Container만 세보더라도, Redis, Spring, Spring Cloud Gateway, Ruby On Rails, Nginx, Certbot, FastAPI 벌써 7가지가 있다. 그런데 여기에 앞서 언급한 Kafka, Grafana, Prometheus, DB Replication, ELK Stack 등 까지 적용하면 수많은 컨테이너가 돌아갈 것이다. 거기에 로드 밸린성까지 적용한다면 우리가 이 컨테이너들을 한번에 관리하는 것은 무리일 것이다. 그래서, EKS, Docker Swarm, Kubernetes같은 자동으로 컨테이너 장애 복구를 도와주는 컨테이너 오케스트라제이션이 필요하다.
추가적으로, 운영체제 과목에서 캡스톤 인터뷰를 하는 과제가 있는데, 이를 대비해서 외국민 팀에서 해당 내용을 자세히 정리한 문서가 있다. 후배들을 위해서 내가 작성한 글이다. 해당 글은 프로젝트 진행을 위해서 어떤 수업을 들으면 좋은지와 Nginx/Apache의 작동 원리, 동시성을 예방하는 방법 (낙관적락, 비관적락, Redis 분산락 등)을 다루고 있다. 혹시라도 관심 있으면 봐주면 좋겠다.
운영체제 관련 질문사항 | Notion
1. 관련이 깊은 소융대 교과목
capstone-design-2024.notion.site
'활동 > 회고' 카테고리의 다른 글
| [회고] 작심심주 오블완 챌린지 시작하기 (0) | 2024.11.06 |
|---|---|
| [회고] 캡스톤 졸업 프로젝트를 마치며 (feat. 외국민 프로젝트) - (1) (1) | 2024.06.22 |
| [회고] 한국지능정보시스템학회 춘계 학술 대회 회고 (4) | 2024.05.12 |
| [회고] 우아한테크캠프 7기 테스트 회고 (0) | 2024.05.09 |



