Serverless란 무엇인가?
많이들 오해 하는데, 서버리스라는게 백엔드 서버가 없다는 뜻이 아니다. 우리가 직접 서버를 관리하지 않아 신경 쓸 필요가 없다는 의미로 서버리스라고 부르는 것이다.
필요한 컴퓨팅 리소스와 스토리지만 동적으로 할당한 다음, 그 부분에 대해서만 비용을 청구하는 모델이다. 사용한만큼 비용이 청구되기 때문에 매우 경제적이며 자원을 효율적으로 사용이 가능. 비용도 굉장히 저렴하다.
300원에 200만뷰 소화하기 - 서버리스 아키텍처 AWS 람다(Lambda) 활용 사례 - 로켓펀치 공식 블로그
로켓펀치에서는 기본적인 웹 서비스 외에 제휴를 통해 로켓펀치의 채용 공고를 위젯 형식으로 노출하는 경우가 있습니다. (예 : 플래텀 오른쪽 사이드바 위젯) 이런 위젯들을 운영하다 보니
blog.rocketpunch.com
위 글은 실제 Serverless 모델을 사용해서 비용을 절약한 사례이다. EC2였으면 엄청난 비용이 나왔을 것을... 200만뷰를 단지 300원에 처리하니 훨씬 저렴하다.
또한, Serverless는 유저가 늘어나면 그만큼 실행 함수도 늘리는 방식이라 스케일링에도 용이하고, 빠르게 개발 배포가 가능하다는 장점이 있다.
Severless Architecture 구현 방식
BaaS(Backend as a Service) : 앱 개발에 있어서 필요한 다양한 기능들 (데이터베이스, 소셜서비스 연동 등)의 API를 제공해줌으로써, 개발자들이 서버 개발을 하지 않고도 빠르게 필요한 기능을 쉽게 구현할 수 있도록하는 것 -> ex) Firebase
FaaS(Function as a Service) : 프로젝트를 여러개의 함수로 쪼개서 매우 거대하고 분산된 컴퓨팅 자원에 준비해둔 함수를 등록하고, 함수들이 실행되는 횟수 만큼 비용을 내는 방식 -> ex) AWS Lambda, Azure Function, Cloud Functions
일반적으로 서버리스라고 하면 FaaS를 칭하는 편이긴 하다. 그리고, 오늘 알아볼 것도 Lambda이다.
AWS Lambda의 여러 기능
1. 다양한 언어를 지원한다
다양한 언어를 지원하지만, 시간이 지나면 특정 버전을 지원하지 않을 수 있음에 유의하자!!! 실제로 내가 인턴하면서 개발 할 때, Python 3.7 버전이 필요했는데, 이제 지원하지 않아서 곤란했던 경험이 있다.
2. 코드를 그냥 업로드하거나 ECR로부터 이미지를 가져와 실행도 가능함

특히, 내가 개발한 버전 언어가 더이상 지원되지 않거나, 라이브러리 용량이 너무 커서 Lambda Layer에 안올라간다면 이미지로 올리는 방법 밖에 없다.
3. 제한시간, 메모리, 스토리지 등 변경 가능 및 환경변수 등록 가능

메모리는 최대 10GB, 디스크는 512MB, 실행시간은 최대 900초, 코드 크기는 최대 250MB

환경 변수가 필요할 경우도 이렇게 사용이 가능하다.
4. Lambda Layer를 통한 외부 라이브러리 사용 가능
Lambda에서 외부 라이브러리를 사용하거나, 드라이버가 필요할 경우 사용할 방법이 없다. (Java는 gradle build하면서 받지만, python이나 nodeJS는 pip 또는 npm으로 미리 받아놔야하기 때문임) → 따라서, AWS Lambda Layer를 사용하여 이를 해결할 수 있음 → 외부 라이브러리의 원본 코드 또는 드라이버를 Layer로 올리면 된다.
하지만, 위에 언급했다 싶이 Lambda Layer에는 크기 제한이 있다. 압축 해제전 250MB, 압축 해제 후 500MB의 크기 까지만 제한한다. 그래서 예를 들어 우리가 동적 크롤링을 위해 Selunium을 쓴다고 가정해보자. 그러면 셀룰리움 라이브러리와 크롬 드라이버를 Lambda Layer에 넣어야 된다. 그런데 크롬 드라이버는 용량이 매우 커서 Layer에 안올라간다. 따라서, Head-less 버전을 구하던가 아니면 Docker Image로 미리 넣어놓는 방법밖에 없다.
5. 함수 작동 트리거 설정 가능
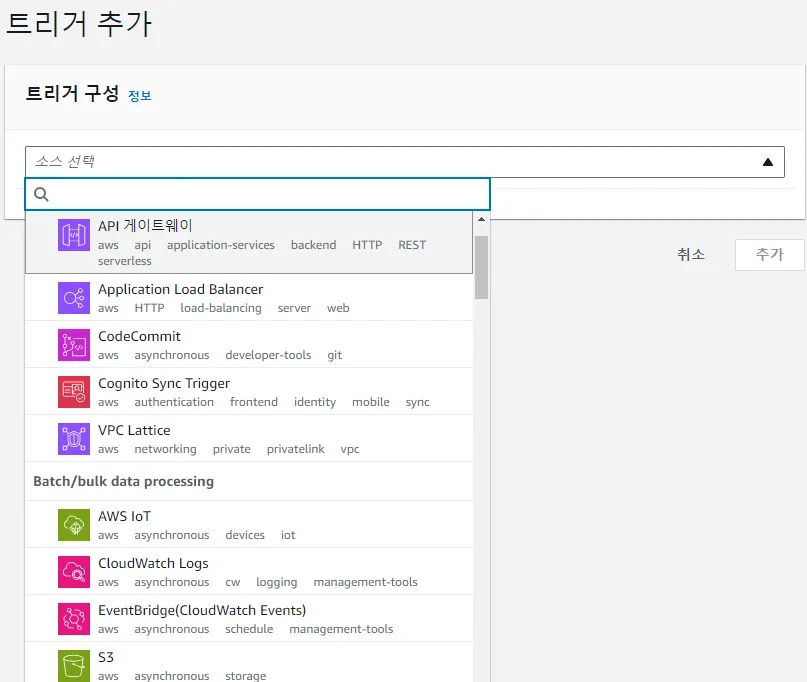
AWS Lambda가 실행되려면 신호를 줘야 할 것이다. 왜냐하면 EC2처럼 24시간 365일 띄워져있는 형태가 아니기 때문이다. 따라서, AWS 서비스와 연계하여 작동 신호를 주는 것이 트리거이다. 트리거는 아래와 같은 예시가 가능하다.
- S3에 파일이 업로드 되거나 삭제되는 이벤트
- API Gateway에 요청이 들어왔을 때
- SQS로 부터 이벤트가 도착했을 때
- CloudWatch Event를 이용하여 특정 시간에만 작동되는 이벤트
이외에도 되게 많다.
6. 컨테이너 방식의 Lambda
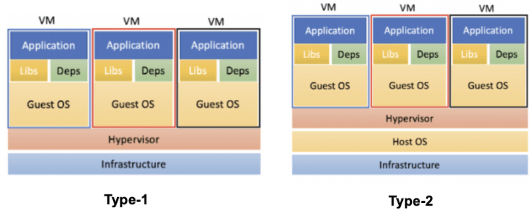
Lambda와 EC2의 작동 방식에도 차이가 있다. EC2같은 경우는 VM으로 작동한다. VM에서 가장 중요한 녀석이 HyperVisor인데, 간단히 설명해서 컴퓨터의 CPU, 메모리 자원등을 여러 VM에 분배해주는 중재자 역할이라고 보면 된다. 그리고, 이 Hypervisor도 Type-1과 Type-2가 있는데, 이는 추후 글을 써서 더 자세히 알아보도록 하고... 어쨌든 EC2는 AWS가 엄청나게 큰 하드웨어 리소스를 구매하고, 이를 Hypervisor Type-1을 통해 사용자들에게 리소스를 배정해주는 VM 방식으로 작동한다.

반면에, Lambda는 Conatiner 방식으로 작동한다. VM과 가장 큰 차이는 VM은 각각 격리된 환경마다 새로운 Guest OS가 올라가는데, Conatiner는 Host의 OS를 공유하는 방식이다. Lambda는 요청이 들어올 때 마다 이렇게 Conatiner를 실행해서 우리가 지정해둔 코드를 실행한다. (요청이 끝나면 바로 컨테이너가 내려가는 것은 아니다. 이 부분은 아래에서 더 자세히 설명할 것이다.)
AWS Lambda로 만들 수 있는 것
1. API Gateway 또는 Lambda 외부 함수 호출 URL을 사용하여 Serverless 형태의 일반적인 API 활용
2. 특정 시간마다 작동되는 작업 (ex : 크롤링, 로그 전송 등)
크롤링이 특정 시간에만 작동되는 것이라면 굳이 EC2에서 24시간 365일 띄워둘 이유가 없다. 따라서, Labmda를 이용해서 특정 시간마다 작동되게 하면 좋다.
3. AWS SNS와 통합하여 특정 시간에 문자를 보내는 기능
AWS SNS를 이용하면 문자를 보낼 수 있다. 따라서, 이를 이용해 인증번호를 메시지로 보낸다던가 Lambda로 가능할 것이다. AWS SES를 사용하여 이메일로도 활용이 가능할 것이다.
4. S3 이미지 리사이징 기능
이 부분은 글을 써둔게 있다.
[AWS] Lambda를 이용한 Image Resizing
소스 코드는 아래에서 확인하실 수 있습니다! GitHub - mclub4/lambda_image_resize: aws lambda로 image resizeaws lambda로 image resize. Contribute to mclub4/lambda_image_resize development by creating an account on GitHub.github.com 1.
mclub4.tistory.com
그런데 위의 방식은 해상도별 이미지를 따로 만들어두는 방식이다. 이렇게하면, 해상도별 이미지 개수가 많아지고, 사진 개수가 많아지면 S3 비용이 많이 비싸질 것이다. 그래서, 실시간으로 이미지 크기를 조절할 수도 있다.
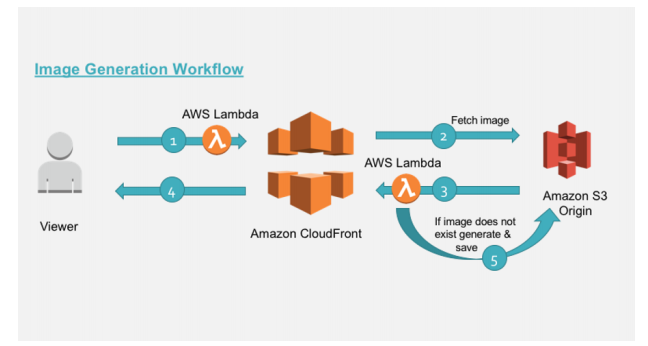
위 그림처럼 Lambda@Edge와 결합하면 된다. Lambda Edge란 CloudFront와 연동하여 엣지 로케이션으로 돌아가는 람다를 의미한다. CloudFront는 AWS에서 지원하는 CDN 서비스로, 캐싱을 통해 사용자에게 좀 더 빠른 전송 속도로 안전하게 컨텐츠를 전송해준다. CloudFront는 세계 여러 곳에 Edge Server(Location)을 두고, Client에게 가장 가까운 Edge Location을 찾아 빠르게 데이터를 전송해준다. 그래서, 이를 이용하여 Edge Location에서 Lambda 함수를 실행해서 이미지 리사이징을 하고, 리사이징된 이미지를 CloudFront에 캐싱해두는 구조이다. 이런 방식을 "On-The-Fly Image Resizing"이라고 부른다.
5. 비디오 파일을 업로드하면 자동으로 인코딩하고 스트리밍 할 수 있도록 하는 서비스
AWS Lambda와 MediaConverter를 사용해 Vod 스트리밍 서비스 개발하기
AWS Lambda와 MediaConverter를 사용해 HLS Vod Steaming을 서비스를 개발해보겠습니다. 목차는 다음과 같습니다. 전체적인 구조 Adaptive Bitrate Streaming에 대해서 1. IAM 역할 만들기 2. S3 설정하기 3. Lambda 만들
develop-writing.tistory.com
6. CloudWatch와 통합한 경고 알림 시스템
CloudWatch에 이상 징후가 감지되면 Lambda를 이용해 우리 이메일, 문자, Slack 등으로 알림 전송이 가능해진다.
7. 챗봇
챗봇도 사용자 요청이 들어올 때만 작동하면 된다. 그런데, 챗봇 자체가 시간이 많이 소요되는데, 거기에 Lambda Cold Start까지 결합되면 오래걸릴 수 있으니 주의 할 것!
8. 쿠키에 따른 A/B 테스트 (Lambda@Edge와 결합)
위에 언급한 Lambda Edge는 쿠키를 검사해 다른 페이지로 리다이렉팅을 시키는 등 A/B 테스트를 수행할 때도 유용하다. A/B 테스트는 A버전과 B 버전 두가지의 버전을 준비해 어떤 것이 사용자 선호도가 더 높은지 테스트하는 방식이다.
AWS Lambda의 단점
1. 리소스 제한
Lambda의 메모리와 처리 시간은 최대 시간이 한정되어 있다. 메모리는 최대 10GB, 처리 시간은 최대 15분이다.
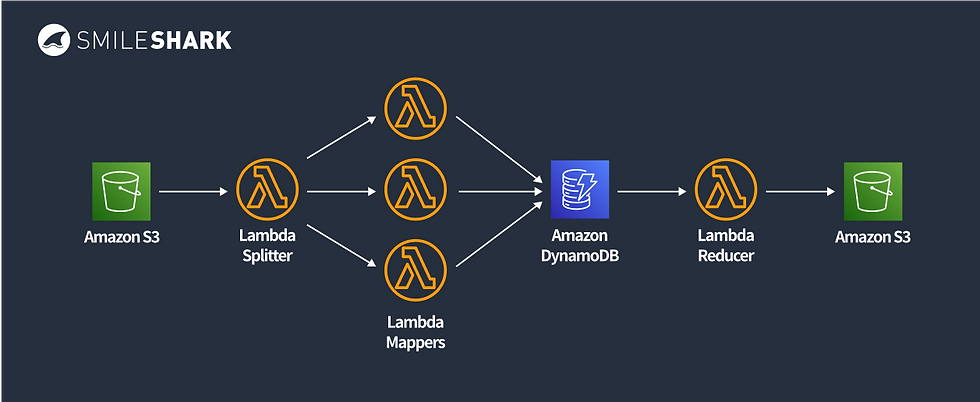
이를 해결하기 위해서 위와 같이 Lambda Spliter를 도입할 수 있다. 함수를 여러개의 람다로 쪼개서 이루어질 수 있도록 구성한다. 이때, 한 람다가 Orchestrator가 된다. 순차적으로 이루어져야 되는 작업일 경우, SQS와 통합해서 전달한다.
2. Clod Start 문제
Lambda는 리소스를 효율적으로 사용하기 위해서 오랫동안 사용하지 않고 있을 경우 잠시 컴퓨팅 파워를 꺼둔다. 그래서, 다시 사용하려고 한다면 실행환경을 구성하기 위해서 시간이 좀 걸린다. 즉, Cold Start 문제가 발생한다.
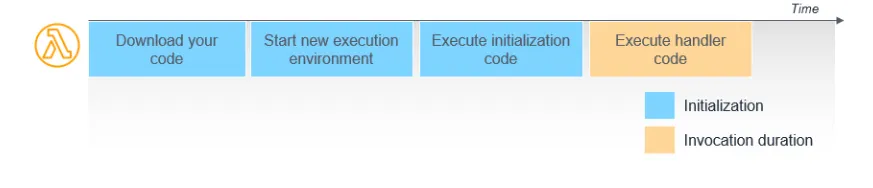
Lambda 핸들러는 크게 4단계를 거친다. 1 ~ 3단계가 Cold Start, 4단계가 Warm Start
- 1단계 : 업로드한 코드를 다운로드 하는 단계
- 2단계 : 새로운 실행 환경을 생성하는 단계 (런타임 및 메모리 구성)
- 3단계 : 전역코드를 실행하는 단계 (Handler 밖)
- 4단계 : 내부 코드를 실행하는 단계 (Handler 안)
이를 해결할 수 있는 방안은 여러가지가 있다.
- Lambda 메모리 늘리기 : Lambda 메모리를 늘림으로서 인스턴스 사양이 올라가 처리 속도가 빨라져서 Cold Start 하는 시간도 개선할 수 있다. 하지만 Lambda는 (메모리 별 가격) * (요청이 처리되는 시간) * (요청수) 만큼 비용이 청구되니 이를 고려하여 늘려야 한다.
- Lambda 함수의 지속적인 호출 : Lambda는 다음 호출이 5분 이내인 경우 후속 호출에 대해서 람다 컨테이너를 재사용한다는 특징이 있다. 따라서, 5분마다 강제로 실행시키면 Cold Start를 해결할 수 있다. 또한, 오래걸리는 코드는 전역으로 빼야된다. (즉, Cold Start 영역에 둬야한다.) CloudWatch에서 5분마다 쏘거나, Route53에서 Health Check Endpoint를 API Gateway로 쏘면 된다. 하지만, 이 부분도 쓸데없는 지출이 늘어난다는 단점이 있다.
- 프로비저닝된 동시성(Provisioned Concurrency) 활성화 : 프로비저닝된 동시성을 활성화하면, 설정한 수 만큼 미리 인스턴스를 초기화 해두고 대기시켜 둘 수 있다. 즉, Lambda가 항상 Warm Start가 된다. 하지만 추가 요금이 나간다.
- 프로비저닝 오토스케일 : 프로비저닝을 트래픽이 급증하는 시간대에 맞춰 오토스케일 하도록 한다. (공식문서 1) (공식문서 2)
- SnapStart : (참고링크)
3. RDB Connection 문제
Lambda는 함수가 호출되면 새로운 컨테이너를 띄우는 방식이기 때문에 별도의 상태를 저장하지 않는다. 즉, Lambda는 이벤트에 의해 트리거 될 때 마다 완전히 새로운 환경에서 호출된다는 것을 의미한다. 그래서 람다가 실행되기 이전과 이후 상황을 컨트롤 할 수 없다. 그래서 RDB Connection 문제가 발생한다. 아래와 같은 상황이다.

이를 위한 해결 방안도 몇가지가 있다.
- 명시적으로 RDS Connection을 종료한다 : 매 요청마다 Connection을 맺고, 종료한다. 그런데 이러면 매번 연결을 맺고 해제하는 비용과 성능에 영향을 미치며, Lambda가 Timeout이 난다는지 등의 상황이 발생하면 실행이 안될 수 있다. 뿐만 아니라, Lambda는 코드를 다 실행하면 그냥 빠르게 종료하기 때문에 연결 해제 로직이 확실하게 작동되었다고 보장하기가 어렵다.
- RDS를 사용하지 않는다 : 애초에 RDS랑 Lambda랑 성격이 잘 안맞는다. 왜냐하면 RDS는 자동으로 요청 수에 따라서 Scale-Out을 해주는 것이 아니기 때문이다. 따라서, 요청수에 따라 자동으로 Scale-out이 되는 DynamoDB 등을 활용하는게 좋다. 뿐만 아니라, DynamoDB는 Connection Pooling이라는 개념이 없어서 연결 수에 대해서 신경쓸 필요가 없다.
- RDS의 max_connection을 늘리고 scale-up 한다 : 잠깐은 해결되는 방식이다. 하지만, 근본적인 해결 방법은 아니다. 그냥 돈으로 때우는 임시방편 해결 방식일 뿐…
- RDS Proxy 사용 : RDS Proxy를 사용하면 자동으로 Lambda가 데이터베이스 연결을 관리하고 기존 연결 재사용이 가능하다. 즉, 여러 Lambda 인스턴스가 동일한 데이터베이스 연결을 공유할 수 있어, 연결 수를 효과적으로 줄일 수 있다. 또한, 연결이 필요할 때마다 새로운 연결을 생성하지 않고, 기존 연결을 재사용하도록 하여 연결 관리의 부담을 줄인다. 다만, 추가 비용이 든다.
4. 동시성 제한
람다는 각 리전별로 동시에 실행할 수 있는 람다함수의 개수를 최대 1000개로 제한하고 있다. 즉, request 수가 1000개가 넘어가면 요청이 지연된다.
- 예약된 동시성 사용 : 특정 함수에 대하여 동시 실행될 수 있는 인스턴스 수를 예약하여 보장하는 기능이다. 쇼핑몰 애플리케이션에서의 예시를 들어보겠다.
- 구매 처리 Lambda 함수에 900의 예약된 동시성을 설정하면, 쇼핑몰에서 동시에 최대 900명의 사용자가 구매 처리를 시도할 수 있으며, 이 작업은 언제나 빠르게 처리됩니다.
- 게시글 작성 Lambda 함수에 100의 예약된 동시성을 설정하면, 게시글 작성은 최대 100명의 사용자만 동시에 할 수 있게 됩니다. 이로 인해 구매 처리에 영향을 미치지 않습니다.
- Limit Increase 요청 : AWS한테 동시 실행 횟수를 늘려달라고 요청하는 것이다.
5. Storage 공간의 부재
임시로 띄워지고 시간이 지나면 내려가는 Container 방식이다 보니깐, EC2의 EBS 같은 영구적인 스토리지가 없다. 그런데, 예를 들어 크롤링을 한다 치면, 크롤링 결과를 인메모리에 저장하거나 아니면 CSV 파일 형태로 임시로 만들고 이를 S3에 전송해야 될 것이다. 특히, 후자의 경우에는 Storage 공간이라는 개념이 없어서 곤란할 것이다.
이를 해결하기 위해서는 람다의 /tmp라는 임시 스토리지가 있다. 이를 이용하면 된다. 나도 인턴할 때, 셀르리움으로 크롤링을 구현하고, 이를 CSV 형태로 만들어서 S3에 저장했어야 했는데, /tmp 영역에 크롤링 결과 CSV를 임시로 저장하고 이를 S3로 전송했다. /tmp 영역은 아래 글을 참조할 것.
[AWS] 📚 람다 /tmp 임시 스토리지 사용 방법
람다 /tmp 임시 파일 추출, 변환, 로드 작업과 PDF 파일 생성 또는 미디어 처리와 같은 데이터 집약적인 애플리케이션일 경우, 대용량 데이터를 잠시 어딘가에 저장해야 할 필요가 생긴다. 단순하
inpa.tistory.com
'BackEnd > AWS' 카테고리의 다른 글
| [AWS] Lambda를 이용한 Image Resizing (0) | 2024.07.07 |
|---|---|
| [AWS] AWS EC2 프리티어 메모리 부족 현상 해결하기 (0) | 2024.05.02 |

